TCP
TCP, Tranmission Control Protocol이라는 이름에서도 느껴지듯 상당히 정교한 control을 포함하는 protocol입니다.
OSI Transport Layer에서 연결 지향이며, 신뢰할 수 있는 데이터 전송을 보장합니다.(Reliable Data Transfer)
Transport Layer에 존재하기 때문에, 종단에만 존재하는 규칙입니다.
시작하기에 앞서 필요한 용어 정의부터합니다.
Socket vs Buffer
Socket : process의 데이터를 Trasport layer으로 전달하는 통로이다. 이때 데이터는 stream 형태로 전달됩니다. process는 한 번에 여러 개의 socket을 가질 수 있으며, 이를 통해서 socket을 가진 다른 process와 통신이 가능합니다.
Buffer : Tranport layer에서 socket을 통해 들어온 데이터를 전송할 때까지 저장하는 장치입니다.(다른 의미도 많지만 여기서는 그렇게 씁니다.)
=> TCP는 데이터를 process로부터, stream 형태로 받기에 구조화되어있지는 않지만, 정렬되어 있다고 간주합니다.
기본
- 송신 시에는 Sequence number를 통해서 현재 보내는 데이터의 순서를 명시합니다.
- 응답 시에는 Acknowledge number를 통해서 받기를 원하는 다음 데이터의 sequence number를 명시합니다.
- 만약 수신 시에 OoO(Out of Order) data가 도착했다면, 일반적으로는 저장하고 있다가 누락된 데이터만 ACK number를 통해서 재요청합니다. (아예 버릴 수도 있지만, 네트워크 환경상 해당 방법이 더 효율적입니다.)
Reliable Data Transfer
network layer에서 제공하는 서비스는 다음 세 가지를 만족시키지 않습니다.
- datagram의 성공적 전송을 보장합니다.
- datagram이 순서대로 전달되었는지 보장합니다.
- datagram 내부의 data의 무결성을 보장합니다.
그러나, TCP는 reliable data transfer service이기 때문에, 데이터는 무결하며, 빈 틈이 없고, 중복이 없으며 순서대로 전달되는 것을 보장합니다. 결론적으로, 전송한 데이터 그대로 수신할 수 있음을 보장합니다.
이를 위해서 TCP는 다음과 같은 기능을 포함합니다.
Timer
여러 개의 timer가 있으면 좋을 수 있지만, 오히려 성능상에 overhead를 일으킬 수 있습니다. 따라서, 단 하나의 timer를 이용합니다.
Timer는 network layer로 해당 segment를 전달할 때 시작시킵니다.
그리고, ACK가 올 때마다, ACK가 오지 않은 data가 있을 경우 다시 timer를 실행시킵니다.
데이터를 전송하고, ACK를 받기까지의 시간을 의미하는 RTT(Round Trip Time)를 측정합니다.
총 3가지 종류의 RTT가 존재합니다.
- Sample RTT : 재전송을 제외한 단 한번의 요청과 반응으로 측정된 RTT를 의미합니다.
- Estimated RTT : RTT의 평균값을 의미하며, $EstimateRTT_{(n)} = (1 - \alpha) \times EstimateRTT_{(n-1)} + \alpha \times SampleRTT$로 계산합니다. (대게 $\alpha = 0.125$를 사용합니다.)
- Dev RTT : SampleRTT와 EstimateRTT 간의 차이 값을 의미합니다. $DevRTT_{(n)} = (1 - \beta) \times DevRTT_{(n - 1)} + \beta \times |SampleRTT - EstimateRTT| $로 표현합니다. (대게 $\beta = 0.25$를 추천합니다.)
이를 통해서, RTT를 측정하고, Timeout을 지정합니다. 처음에는 1초를 기반으로하여, 실패 시에는 두 배로 늘리다가 어느정도 계산이 완료되면 $TimeoutInterval = EstimatedRTT + 4 \times DevRTT$를 이용하여 해당 시간을 지정합니다.
만약, timeout이 발생한다면, 가장 sequence number가 낮은 데이터를 재전송합니다. 이때, 위에서 설정했던 timeoutinterver 대로 설정하는 것이 아닌 현재에 두 배로 설정하는 것을 원칙으로 합니다.
Fast Retransmit
timeout에만 기대는 재전송 방식은 상대적으로 많은 시간을 소요할 수 있다. 따라서, segment가 lost되면, 이러한 timeout 방식이 통신의 지연을 더 악화시킬 수 있다. 다행히도, TCP에서는 packet의 손실을 timeout이 발생하기 전에 중복되는 ACK를 통해서 알 수 있다. 이것이 발생하는 이유는 수신단에서 데이터의 gap이 발생하였을 경우, TCP가 negative ACK를 지원하지 않으므로, 받고자하는 데이터의 sequence number를 ACK를 통해서 전달한다. 이는 이미 송신단에서 받은 ACK이므로 중복된다. 따라서, 이를 통해서 송신단에서는 데이터의 손실이 발생했음을 알 수 있다. 하지만, 이때 하나의 중복만으로 재전송을 수행하는 것은 아니다. 일반적으로 세 번의 중복이 발생(즉, 동일한 ACK가 4번 옴)할 경우에 fast retransimit을 수행한다. 이것은 후에 배울 slow start를 최대한 피하기 위함이다. 왜냐하면, 단순 중복만으로는 순서가 그저 바뀌기만한 것인지 알 수 없기 때문이다.
Go back N vs Selective Repeat
TCP에서는 전송을 하였지만, 응답이 없는 byte에 대해서만 sequence number에 대해서만 유지합니다. 이 때문에 GBN이라고 볼 수도 있습니다. 하지만, OoO 데이터를 버리지도 않고, 재전송 시에도 전체를 다 보내는 것이 아니니 SR로 볼 수도 있습니다. 따라서, 우리는 TCP는 어느 한쪽에 속하는 것이 아닌 Hybrid 형태라고 정의할 수 있습니다.
Three way handshaking

두 host간에 데이터를 전송하기 위해서, 서로를 식별하는 단계가 필요합니다.(각자에게 맞는 자원을 할당하고, socket을 열어 두어야 하며, network 통신이 가능한지 여부를 확인해야 함) 따라서, 다음 세 단계에 걸쳐서 통신 준비를 시행합니다.
- client는 특별한 segment(SYN segment)를 전송한다.
- application data를 포함하지 않습니다.
- SYN bit를 1로 설정합니다.
- SEQ field에 client_isn(Initial Sequence Number)를 random하게 선택하여 설정합니다. => 공격을 피하기 위함.
- server에 데이터가 도착하면, 이에 응답하며, 같이 특별한 segment(SYNACK segment)를 전송한다.
- application data를 포함하지 않습니다.
- SYN bit를 1로 설정합니다.
- ACK field를 client_isn + 1로 설정합니다.
- SEQ field에 server_isn을 random하게 선택하여 설정합니다.
- 만약, 이 과정에서 port번호가 알맞지 않다면, RST bit를 1로 하여 재전송을 거부합니다.
- client는 세 번째로 특별한 segment를 전송하며 이에 응답한다.
- SYN bit를 0로 설정합니다.
- ACK field를 server_isn + 1로 설정합니다.
- SEQ field를 client_isn + 1로 설정합니다.
- payload에 전송하고자하는 데이터를 포함합니다.
연결 종료 시
- client가 연결을 종료한 후, 특별한 segment를 server process에게 전송한다.
- FIN bit를 1로 설정합니다.
- server는 바로 이에 대한 ACK를 전송합니다.
- server가 연결을 종료하였다면, 특별한 segment를 client에게 전송합니다.
- FIN bit를 1로 설정합니다.
- client는 이에 대한 ACK를 전송합니다. 만약, 해당 ACK가 loss될 것을 고려하여 일정 시간 기다립니다. (대게 30초 ~ 2분)
SYN flood attack
2단계까지 수행한 상태에서 만약, client가 ACK를 보내지 않는다면, server는 반정도 열린 connection(client_isn을 저장하는 queue로 메모리를 사용)을 유지하기 위해서 자원을 소비할 수 밖에 없습니다. 이것을 악용하여 고의적으로 다수의 요청을 server에 보내어 서비스 이용을 제한한 것이 최초로 기록되어진 DoS 공격으로 전해집니다.
다행히도 이는 SYN cookie라는 방법을 통해서 현재에는 발생하지 않는 문제입니다. segment의 정보에 hash function을 적용하여 암호화하여 sequence number를 SYNACK 시에 전송하고, 저장은 하지 않습니다. 그리고 돌아온 데이터를 다시 hash function으로 취하고 + 1을 한 값이 돌아온 ACK 값과 동일하다면, 연결을 수행합니다.
Flow control
receiver buffer가 sender에 의해서 overflow가 발생하는 것을 방지하기 위한 방법이다.
이를 위한 핵심 기술은 receive window($rwnd$)이다. 이는 전송자에게 얼마나 buffer에 여유공간이 존재하는지를 알리는데 사용된다.
기본적으로 다음 식은 항상 성립한다는 것을 알 수 있다.
$LastByteRcvd - LastByteRead \leq RcvBuffer$
좌항은 buffer에 남아 있는 읽지 않은 byte의 양을 우항은 receive buffer의 크기를 의미한다.
또한, 다음과 같이 $rwnd$를 계산할 수 있다.
$rwnd = RcvBuffer - (LastByteRcvd - LastByteRead)$
이렇게 계산된 $rwnd$는 ACK와 함께 전송자에게 전달되며, 그렇게 되면 전송자는 다음을 유지함으로서 flow control을 할 수 있다.
$LastByteSent - LastByteAcked \leq rwnd$
여기서 좌항은 응답이 오지않은 전송 byte를 의미합니다.
여기서 문제가 하나 발생할 수 있는데 바로, $rwnd=0$이고, ACK를 보낼 것이 없다면, receiver는 이를 알릴 수가 없다. 따라서, 송신자는 이를 확인하기 위해서 one byte의 데이터를 지속적으로 보내며, $rwnd$가 계속 0인지 확인한다.
Congestion control
IP network의 혼잡을 측정하고, 이를 바탕으로 전송량을 조절하는 방법이다.
network에서 congestion 관리가 중요한 이유는 전송에 미치는 영향이 예측하기 어려우며, 심할 경우 지수적으로 수신량이 감소하며, 받을 수 없는 지경에 이를 수도 있기 때문이다.

$\lambda'_{in}$: application이 sender buffer에 전송한 데이터의 양
$\lambda_{out}$: application이 receiver buffer로 부터 받은 데이터의 양
이를 해결하기 위해서, network layer 기반으로 해결하는 방법(choke packet, router marking, etc...)도 존재하지만, TCP의 방법으로 수행하는 방법을 알아볼 것이다.
따라서, 우리는 다음과 같은 질문에 대답할 수 있어야 한다.
- 어떻게 TCP sender가 통신 중에 전송 비율을 조절할 수 있는가?
- 어떻게 목적지와 자신 사이에 congestion이 발생했다는 것을 알 수 있는가?
- 종단간 congestion으로 인해 전송률을 변경하기 위해서 무슨 알고리즘을 사용할 것인가?
1. How can TCP control congestion?
답은 Cogestion window이다. TCP에서 sender는 congestion window(cwnd)라는 별도의 변수를 추가로 관리한다.
기존의 flow control 시에 사용하였던, $LastByteSent - LastByteAcked \leq rwnd$를 변형하여 다음과 같은 식으로 사용합니다.
$LastByteSent - LastByteAcked \leq min(cwnd, rwnd)$
해당 congestion window를 조절하는 방법은 3번에서 다룹니다.
2. How can TCP discover congestion?
congestion에 의해서 발생하는 현상을 알면 이는 간단하게 풀린다. network layer에서 통신이 혼잡하다는 것은 router에서 overflow가 발생하여 loss 되었다는 것과 동일합니다. 따라서, TCP는 데이터의 loss를 congestion으로 받아드립니다. 그리고, 이러한 loss는 위에서 설명했던 것처럼 timeout, three duplicated ACKs를 통해서 알 수 있습니다.
3. How can TCP effectively control network?
여기서 TCP의 최대목적을 제시하겠습니다. 그것은 통신의 혼잡을 최소화하여 데이터 손실을 없애고, bandwidth를 최대한 활용하여, 효율적으로 데이터를 전송하는 것입니다.
이를 위해서는 congestion window의 크기 조절이 매우 중요합니다. 이에 대한 알고리즘을 3가지 소개합니다.
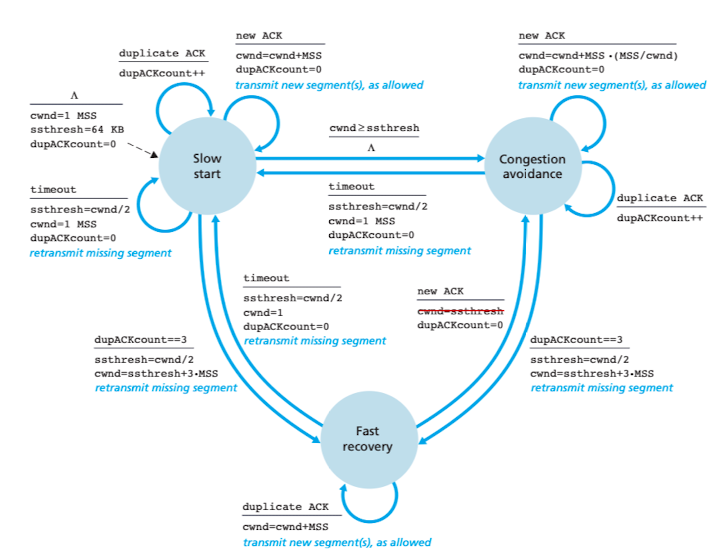
- Slow Start
이를 위해서 ssthrest(Slow Start Threshold)라는 변수가 필요합니다. 지금은 그냥 이름 뜻대로 slow start의 임계점이라고 생각하고 넘어갑시다.
처음에는 cwnd의 크기를 1MSS(Maximum Segment Size)에서 시작해서 매 ACK마다 1MSS만큼 전송량을 늘리는 방식입니다.
따라서, 처음에 1MSS로 cwnd를 설정하여 전송하였다면, 다음에는 2, 그 다음에는 4 이런 식으로 지수적으로 상승합니다.
이렇게 지수적인 상승은 loss가 발생하거나 ssthresh(Slow Start Threshold)에 도달할 때까지 계속됩니다. 총 3 가지로 나눌 수 있습니다.
- timeout이 발생했을 경우
sshtresh를 현재 cwnd의 반으로 설정한 후, 다음 cwnd를 1로 설정합니다. 그 후 같은 동작을 반복합니다. - sshthresh에 도달한 경우
임계점부터는 congestion의 위험이 있으므로 천천히 전송량을 증가시킵니다. 따라서, 이 후에 나올 congestion avoidance 상태로 변경되게 됩니다. - three duplicated ACK가 발생한 경우
이 경우에는 두 가지 방식이 있습니다. timeout가 똑같이 대처할 수도 있고, 아니면 이 후에 나오는 fast recovery 상태로 들어갈 수 있습니다.
성능상 fast recovery가 추천됩니다.
- Congestion Avoidance
해당 모드에서는 한 번에 cwnd 전송이 끝난 후에, 1만큼만 cwnd를 상승시키는 방식입니다. 따라서, RTT당 1cwnd의 상승으로 이해하면 쉽습니다. 따라서, 상당히 조심스럽게 cwnd가 상승합니다.
이 경우에 2가지의 경우의 수가 존재합니다.
- timeout이 발생한 경우
ssthresh(cwnd / 2)를 기록한 뒤, slow start로 진입합니다. - three duplicated ACK가 발생한 경우
slow start와 동일하게 선택이 가능합니다.
- Fast Recovery
일단 현재 sstresh를 현재 cwnd의 반으로 측정합니다. 그리고, cwnd는 sstresh 값에 3을 더한 값으로 이동합니다.(보통 다 반이라고 하는데 여기에는 타당한 이유가 있습니다.)
그리고, 중복된 ACK가 올때마다 cwnd의 크기를 1씩 늘립니다. 즉, 이 순간에는 중복된 ACK가 온다면, slow start 처럼 동작하고, 새로운 ACK가 온다면, congestion avoidance 모드로 이동하며, timeout이 발생한다면, slow start 모드로 이동하며, cwnd값이 1이 됩니다.
여기서 위에서 ()한 3을 추가해준다는 내용에 대한 답을 알 수 있습니다. (이미 3번 중첩되었기 때문에 3을 추가해주는 것입니다.)
아래 그림은 fast recovery를 적용한 TCP Reno와 적용하지 않은 TCP Tahoe를 비교하는데, 다음과 같은 차이를 보여주는 것을 알 수 있습니다.

이렇게 TCP의 congestion control 방식이 안정을 찾으면 선형적으로 증가하고, error 시에 지수적으로 감소하는 것을 볼 수 있다. 따라서, 이를 AIMD(Additive Increase, Multiplicative Decrease)라고 합니다.